Wie du ChatGPT lokal auf deinem PC betreiben kannst – und was Kobolde damit zu tun haben.

![]() Maik hier.
Maik hier.
ChatGPT ist schon cool – Keine Frage. Es eröffnet einem Möglichkeiten, die vor einigen Jahren nichtmal denkbar gewesen wären. Ich gehöre noch zu der Generation, die erst im Laufe ihrer Jugend ein Handy bekommen hat. Damals noch n klassischer Block mit kleinem Display und polyphonen Klingeltönen. Ach, mein altes Sony Ericsson W200i…. Aber ich schweife ab. Jedenfalls gab es Früher kein ChatGPT. Wir mussten uns alles mühsam selber ergooglen. Von meinen älteren Geschwistern und meiner Mutter höre ich gar Horrorstories von einer Zeit vor dem Internet. Da musste man scheinbar noch in die Bücherei gehen um Sachen herauszufinden…
Auch ChatGPT hat seine Grenzen. Und seine Moral.
Jeder, der sich ein wenig mit dem Chatbot beschäftigt hat, weiß wo die Einschränkungen liegen.
Nach einer gewissen Menge an Anfragen ist für eine Stunde erstmal Schluss – Schlecht, wenn man ne straffe Deadline hat und auf das Ergebnis angewiesen ist. Auch reagiert der Contentfilter von OpenAI aus meiner Erfahrung manchmal etwas zu sensibel. Texte für Disstracks im Stil von Haftbefehl gehen nur, wenn sie bitte nicht die Gefühle des Adressaten verletzen, der in dem Moment neben mir sitzt. Nun Gut.
KI ist aktuell noch ein Verkäufer-Markt. Die Technik ist neu, hochkomplex und: Rechenintensiv. Verdammt Rechenintensiv. Zur Textgeneration nutzt ChatGPT sogenannte „Token“. Im KI-Verständnis sind das Textschnipsel von 3-5 Zeichen, die entsprechend bewertet werden (DAS ist die KI). Wird ein Token als „Gut“ bewertet, wird es verwendet. Der sich Stück für Stück aufbauende Text bei ChatGPT – Das sind die Token, die in Echtzeit ausgespuckt werden! Dass das Ganze schnell Vonstatten geht – Das braucht eben diese Rechenleistung und ist damit teuer.
Folglich limitiert OpenAI wie viel Scheiße ich mit dem Ding in ’ner Stunde treiben darf um mich zu amüsieren und deshalb, vermutlich auch wegen Leuten wie mir, ruft OpenAI für weitere größerflächigere Nutzung Gebühren auf.
Folgt dem Regenbogen…
Neben dem Topf voll Gold findest Du dort idealerweise einen Kobold. Was der mit ChatGPT zu tun hat, erkläre ich dir:
KoboldCPP, heißt hier das Zauberwort.
Hierbei handelt es sich um einen weiterentwickelten Fork des Projektes LLaMA.cpp – Einer Implementierung freier LLMs (Large Language Models) in C++. Wenn man sich LLaMA als die Technik vorstellt, dann ist KoboldCPP das Produkt.
KoboldCPP ist eine KI-Software zur Text-Generierung, welche vollständig lokal läuft und nur aus einer einzigen .exe Datei besteht. Du brauchst lediglich eine moderne nVidia Grafikkarte (je Leistungsfähiger, desto besser) und ein Sprachmodell – Schon kanns losgehen. (AMD geht auch, sagt das Repo – Das habe ich aber nicht ausprobieren können)
Zu finden ist das Projekt auf Github. Am Ende dieses Posts findest du eine Verlinkung.
Mein Setup
Mein System verfügt über folgende Hardware:
- CPU: AMD Ryzen 7 3800X
- GPU: nVidia GeForce RTX 3060 Ti
- RAM: 32GB DDR4
- OS: Windows 11
Das nur als Vergleichswert. Je nachdem wo dein PC im Vergleich liegt, kannst du grob einschätzen, welche Performance du erwarten kannst.
KoboldCPP
Die erste Herausforderung, vor der Du wahrscheinlich stehen wirst ist es, den richtigen Download zu finden.
KoboldCPP kommt in mehreren Varianten. cuda, nocuda, und alles für Linux und Windows.
Als Faustregel ist koboldcpp_cu12.exe die Datei der Wahl. Die setzt auf Cuda12 auf, einer aktuellen Library von nVidia. Mit einer aktuellen RTX-Karte solltest du da keine Probleme haben – Check im Zweifel mal deinen Grafikkartentreiber ab, wenn du unsicher sein solltest.
Hast Du die richtige Version heruntergeladen und dir ein passendes Sprachmodell dazugelegt, kann es losgehen.
Für meine Testzwecke nehme ich das Modell M7-Evil-7b-GGUF, welches bei Huggingface heruntergeladen werden kann (Link unten).
Die Projektseite schickt folgenden Disclaimer voraus:
Warning #2: Can insult/berrate user without provocation or warrant at times during image identification so beware.
Perfekt also für meine Disstrack-Quest.
Let’s get started!
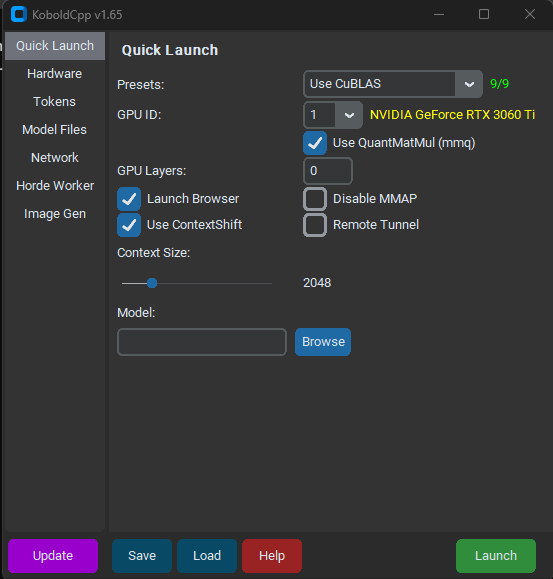
Mit einem Doppelklick auf die .exe öffnet sich erstmal ein leeres Kommandozeilenfenster. Nach ein paar Sekunden heißt es dann Welcome to KoboldCpp und die GUI erscheint. Hier befinden wir uns nun im Reiter „Quick Launch“.
Passt für mich, mehr als bisschen Belustigung will ich gar nicht – Da reicht der Quick Launch für aus.
In diesem Menü müssen wir uns 5 Punkte genauer anschauen und einstellen: Presets, GPU-ID, GPU-Layers, Context Size und Model. Wofür die da sind?
- Presets: Welche Technologie wollen wir nehmen? Das bestimmt die allgemeine Geschwindigkeit der Textgeneration. CuBLAS nutzt Cuda. Das wollen wir.
- GPU ID: Hier sollte in Gelb Deine Grafikkarte stehen. Tut sie das, hast Du die richtige ID. Glaub mir, du willst das nicht auf deiner Integrierten CPU-Grafik machen.
- CPU-Layer: Keine Ahnung was das macht. Je größer, desto schneller. Zu groß und dein PC stürzt ab.
- Context Size: Jetzt wirds etwas komplexer. „Context“ beschreibt hier den Umfang an Vorwissen, den das Sprachmodell in Token zu jeder Abfrage mitgeschickt kriegt. Auf dem Bild haben wir 2048 eingestellt, also werden zusätzlich zu deiner Anfrage die letzten 2048 Token mitgeschickt. Je größer diese Zahl, desto mehr „erinnert“ sich die KI. Zu groß, und sie kann anfangen zu halluzinieren…. Und dein PC kann abstürzen.
- Model: Welches Modell wollen wir nutzen? Hier wählst du das heruntergeladene Modell deiner Wahl aus.
Für mich haben sich folgende Parameter bewährt:
- CPU-Layer: 27
- Context Size: 16384
Mit einem Klick auf „Launch“ passiert jetzt eins von zwei Dingen:
Entweder, das Kommandozeilenfenster zeigt einen Fehler in Richtung „Cuda out of Memory“ – Heißt, Dein VRAM ist verplant. In dem Fall, starte den PC einmal Neu oder schraub die Einstellungen runter.
Oder, du kriegst eine Meldung „Please connect to custom endpoint“ und es öffnet sich ein Browserfenster.
Sollte letzteres der Fall sein: Willkommen bei KoboldCCP!
Was kann KoboldCPP denn nun?
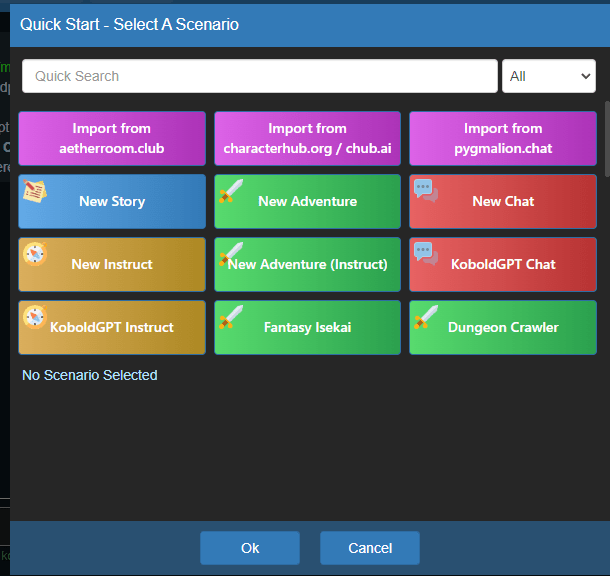
In der Weboberfläche angekommen, hast du die Möglichkeit, ein Szenario zu laden. KoboldCPP kann bpsw. im Instruct-Modus agieren, also so wie ChatGPT – Im Adventure-Modus, also so wie ein Dungeonmaster bei DnD – im Story-Modus, welcher sich für’s Schreiben von Geschichten anbietet oder im Chat-Modus, wo die KI eine Person imitieren wird.
Für unser Beispiel, einen Disstrack im Stil von Haftbefehl brauche ich den Instruct-Modus – Also wähle ich diesen aus. Das KoboldGPT-Preset bringt hier schon viele Voreinstellungen mit, die der KI ein Selbstverständnis ähnlich wie ChatGPT geben.
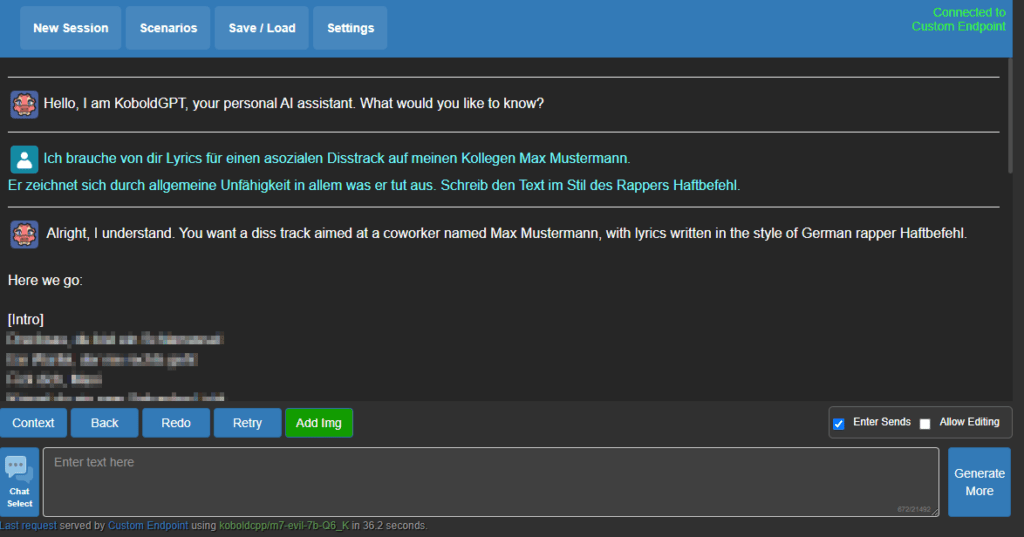
Nun… Das Ergebnis erspare ich dir an dieser Stelle. Nur soviel: Das Evil7b-Modell würde ChatGPT die Schamesröte ins Gesicht treiben.
In den Settings lassen sich weitere Einstellungen vornehmen – Beispielsweise die zu generierende Textmenge. Standardmäßig liegt diese bei 256 Tokens, die kann aber nach belieben hoch- oder runtergesetzt werden. Über den Button „Generate More“ lässt sich die Antwort immer weiter verlängern.
Conclusion
Meine Performance lag hier bei 2,48 Token / Sekunde – Man muss also deutlich länger auf eine Antwort warten als bei ChatGPT. Aber immerhin ist es umsonst…
Denkt dran: With great power comes great responsibility – Treibt nicht zu viel Schindluder mit der Technik! Und falls doch, ihr habt’s nicht von mir!
-Maik
Ressourcen
Github-Repo: https://github.com/LostRuins/koboldcpp
Sprachmodell Evil7b: https://huggingface.co/InferenceIllusionist/M7-Evil-7b-GGUF